Pick Me: Slowing the growth of my TBR
Every time I go to a bookstore, I pick up five different books. But which one will I like the most? This project will help me responsibly slow the growth of my TBR stack by estimating the rating I would give each book, using my own reading history as a data source.
NOTE: sign ups are disabled to keep my costs down ;)

Learning Goals
- Create a new project from scratch, no templates
- Lean heavily on coding assistants, in particular Every’s compound learning Claude plugin
- Create a web-accessible site to solve a real problem I have
Links
Stack/Tooling
- ChatGPT for initial project plan
- Every’s Compound Engineering plugin
- V0 for UX design and iterations
- Claude Code VSCode plugin
- Postgres (hosted on Neon)
- Vercel for deploys and hosting
- Typescript
- Next.js for routing (front and backend)
- ngrok for local tunneling, used for local mobile testing
- OpenLibrary for most book data
- Google Books for additional book data
Main Takeaways
The compound engineering plugin is token hungry, but I’m very impressed by the thoroughness of it’s planning capabilities.
The key skill of a software developer is expressing intent.
Curiosity will increasingly become the key quality that helps engineers grow in their career.
Reflections
My primary goal for this project was to lean heavily into modern AI-driven coding workflows. As the landscape has shifted significantly since I was a full-time developer, I wanted to push these tools to their edges—identifying what works, what breaks, and where the “diminishing returns” begin. Understanding these boundaries helps me discern when to step in manually versus when to rely on an agent.
The Stack & UI Scaffolding
The power of V0 was impressive. I used Claude to build the initial scaffold and establish the API. This workflow is a bit backward for a UI-first tool like v0, but it worked well. I used Claude to meta-prompt the instructions for v0 once the skeleton app existed. I think having a skeleton built helped me get better clarity about my UI needs, which made working with V0 much more efficient. Clear API boundaries helped as well.
After some minor tweaking in v0, the initial UI was very close to what I wanted. I was able to lift the UI files directly into my codebase and then had Claude work page-by-page to integrate the backend logic. Interestingly, once a UI paradigm was established, adding new features in that style became trivial; I could iterate directly in the code with Claude without returning to v0.
Workflow Orchestration
I leaned heavily on Every’s Compound Learning plugin for Claude. While the plugin can be triggered via slash commands, I found it difficult to recall the precise sequence of the workflow. However, I discovered that if I simply instructed Claude to use the plugin, it would intelligently select the correct step, removing the cognitive load of manual invocation. One minor friction point: I still had to explicitly prompt it to record learnings; I’d prefer for that “memory” function to be more autonomous.
The Planning-First Paradigm
Putting 80% of the effort into the planning phase paid off, but it highlighted a specific risk: AI agents suffer from the same “author validation” and pliancy as LLMs. If I proposed a flawed architectural path, the agent often gladly followed me down the rabbit hole, requiring painful unwinding later.
I found the most success by outlining outcomes and constraints, then letting Claude perform the research. This reinforces my belief that the core key skill of an engineer is expressing intent whether to a compiler, an agent, or a human reader. Clearer intent invariably leads to more resilient solutions.
The Cost of Context
A planning-focused workflow is significantly more “token-hungry” than a code-focused one. This makes sense to me in retrospect: generating comprehensive documentation and architectural specs produces more output tokens than most code changes. I found myself aggressively monitoring token usage and scheduling development around Anthropic reset windows. To mitigate this, I began leveraging multiple sources: using ChatGPT to define the problem space and research best practices, before moving to Claude for the specific implementation.
The Trust Gap and “Prompt-Reviewer” Bias
Offloading so much labor to an agent introduces a dangerous level of “rubber-stamping.” It is incredibly easy to approve a PR without inspecting the logic or testing the edge cases. This is a classic resiliency issue caused by automation: the more automation leads to a decay in system knowledge by operators, ultimately making the system less safe and more difficult to operate.
We need to bring a healthy skepticism to every change. In traditional engineering, we say an author shouldn’t review their own code. We need a new corollary: you should not review a change that you prompted. In both cases, your assumptions and blind spots are already baked into the intent you expressed.
Curiosity will be a help mitigate some of these issues.
Compliance and Control
During long sessions, the required approvals becomes a bottleneck. It is tempting to grant agents greater autonomy, but the part of me that has worked with enterprise compliance shudders at the thought. This feels like the next generation of the “should developers have prod DB access?” debate. This may also be operator error, maybe there are better permission settings I could leverage. This may also be a tooling issue, I’m interested in using Ralph for a fully hands off development experience.
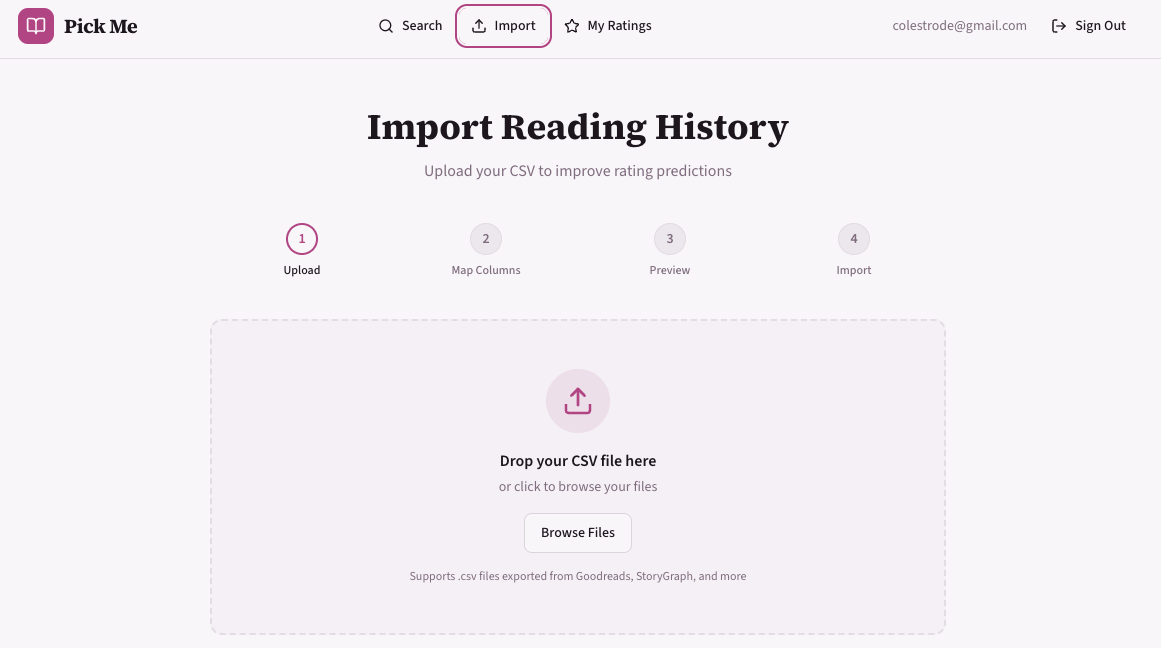
The Data Hurdle
In the end, I built exactly what I set out to create, but the biggest hurdle remains data. Finding high-quality, free sources for book genres and themes is difficult. I eventually settled on a manual AI enrichment pipeline:
- Export data from Goodreads.
- Batch the data into 20-row increments.
- Use a Custom GPT to annotate the books with “community tags.”
- Upload the enriched data into the app.
While not a scalable solution, it was “good enough” for a hobby project. However, it has me thinking about future iterations involving more sophisticated data pipelines, perhaps exploring vector encoding and ANN (Approximate Nearest Neighbor) search capabilities.
While this workflow got me good data on an individual book level, the tags didn’t have a fixed taxonomy, which reduces the accuracy of matching. I think I’ll return to this project in the future to improve on this part of the workflow.
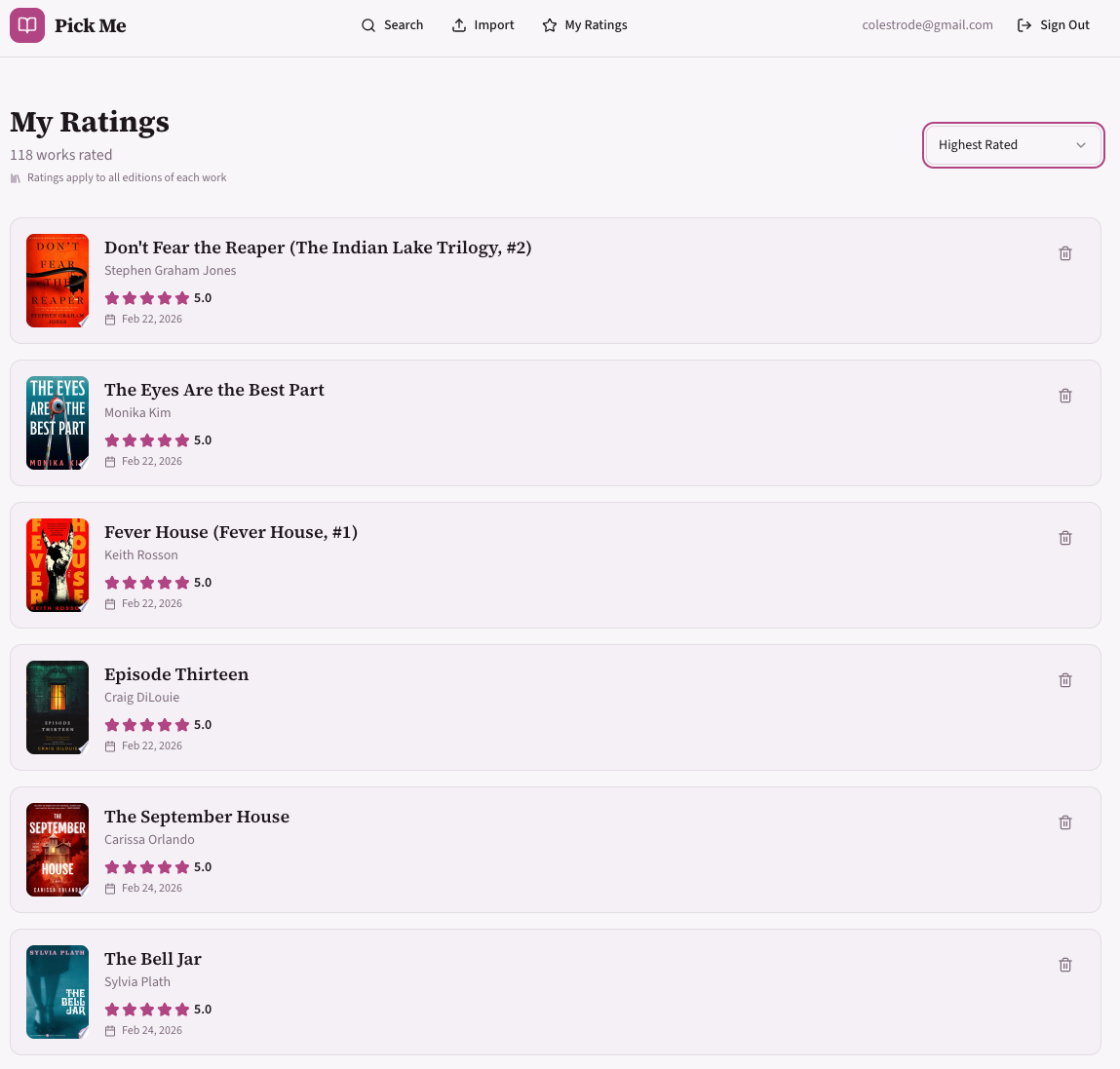
Screenshots